V-IRL: Grounding Virtual Intelligence in Real Life
An open-source framework for
embodied agent
and
open-world computer vision
research.
Develop practical agents and test foundation models in virtual real world cities across the globe, grounded with real geospatial data and street view imagery.
There's a massive gap between the text-centric digital environments of current AI agents and the sensory-rich world we humans inhabit.
To develop agents that can operate flexibly and reliably in real-world settings, we must bridge this gap and embody agents in an environment that necessitates the nuanced perceptual understanding required in the real world.
Naturally, this problem has long been studied in robotics, with agents embodied physically in the world; however, the physical constraints and cost of real hardware prohibit scaling up agents and testing them in diverse environments beyond the lab.
To address this challenge, we introduce V-IRL,
a scalable platform enabling agents to interact
with a virtual facsimile of the real world.
Leveraging mapping, geospatial, and street view imagery APIs (see §System Fundamentals), V-IRL
embeds agents in real cities across the Earth.
To showcase the capabilities our platform enables, in §Agent Exemplars, we use V-IRL to instantiate a series of agents
that solve various practical tasks, grounded with its sensory-rich perceptual and descriptive data.
Our platform also functions as a vast testbed for measuring progress in
open-world computer vision and embodied AI with unprecedented scale and diversity—providing structured access to
hundreds of billions of images spanning the entire globe.
Google Street View alone has >220 billion images as of May 2022, and there are numerous other sources of imagery and data that can be incorporated to enrich the environment.
https://blog.google/products/maps/street-view-15-new-features/
In §V-IRL Benchmark, we use V-IRL to construct an initial benchmark of "open-world" vision models on a truly open-world distribution.
V-IRL Agent Exemplars
To demonstrate the versatility of the V-IRL platform, we use it to instantiate several exemplar agents virtually in real cities around the globe and engage them in various practical tasks.
For illustration, we give V-IRL agents character metadata, including an 8-bit avatar, a name, a short bio, and an intention they are trying to accomplish.
For a deeper dive into V-IRL's components and the capabilities they enable, see §System Fundamentals.
Each subsequent agent and their task is designed to reveal a new capability of the platform.
We highlight the specific V-IRL capabilities being employed throughout using tags and correspondingly colored sections:
V-IRL agents can utilize visual detectors, VLMs and LLMs to iteratively perceive, decide, and interact in the environment.
Ling: Takeaway
V-IRL agents can collaborate to solve complex tasks that are beyond their individual expertise.
Diego: Takeaway
V-IRL agents can collaborate with users to solve complex tasks that require understanding the user's internal state.
Earthbound Agents
Agents using the V-IRL platform inhabit virtual representations of real cities around the globe. At the core of this representation are geographic coordinates corresponding to points on the Earth's surface.
Geographic Coordinates: Latitude and Longitude of the Earth
Figure source: Wikimedia Commons
With these geographic coordinates as a link between digital media and the real world,
V-IRL agents ground themselves in the world using APIs for maps, real street view imagery, information about nearby destinations, and much more.
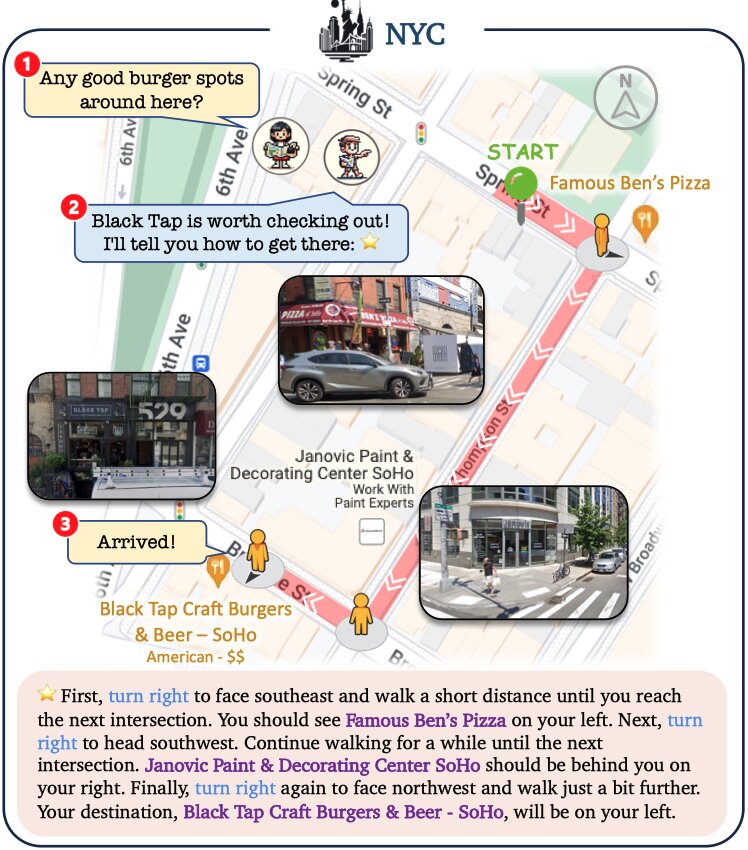
Peng: Visiting Student
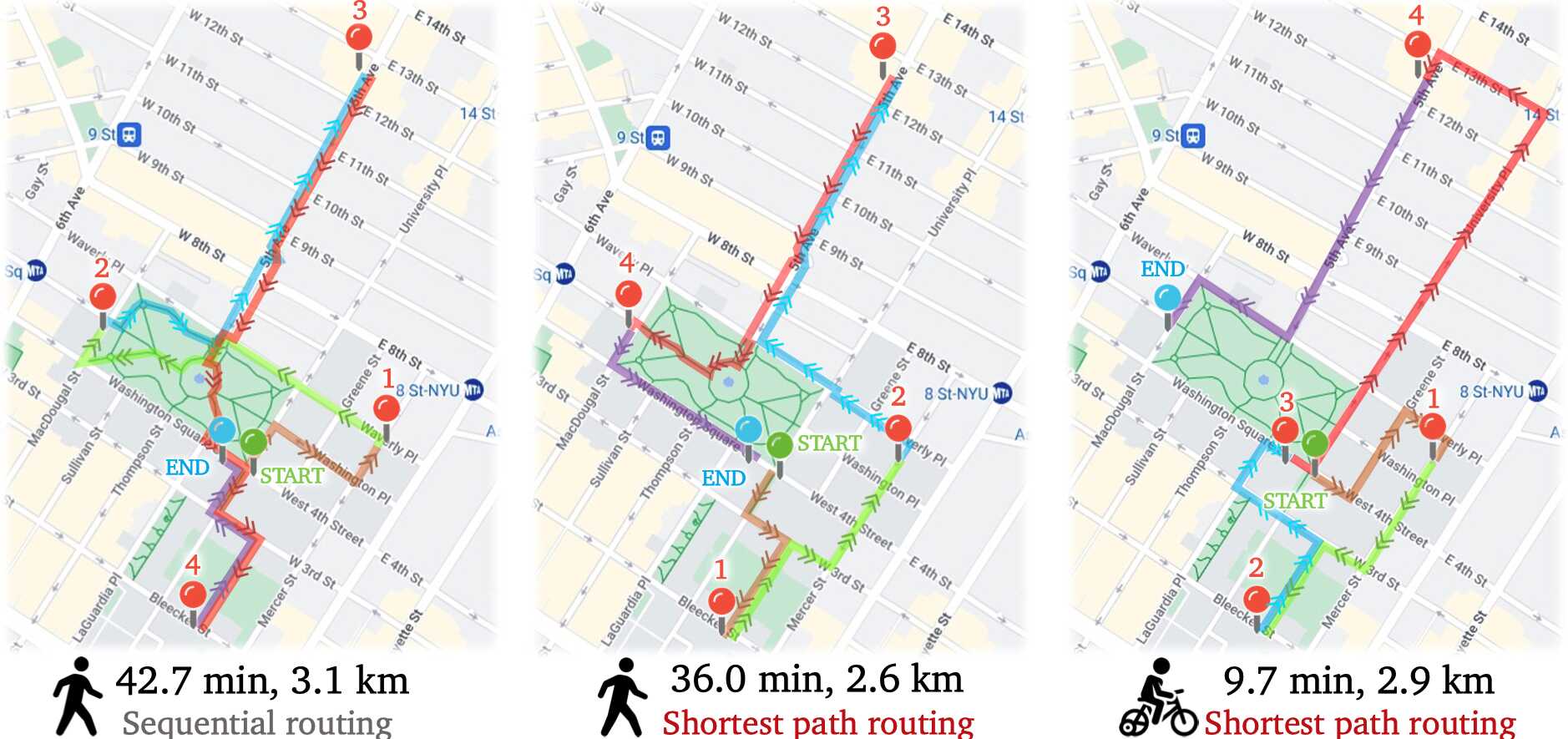
Peng needs to visit several locations throughout NYC to get documents signed for registration as a visiting student...
Leveraging Geolocation & Mapping capabilities, Peng saves 7 minutes by walking along the shortest path as opposed to in order waypoint visitation.
Finding the shortest path for Peng to travel to five places.
Takeaway
V-IRL instantiates agents with real geospatial information, and enables useful tasks like route optimization.
Language-Driven Agents
To tackle more complex tasks, we follow the pattern of language-driven agents . LLMs enable agents to reason, plan, and use external tools & APIs.
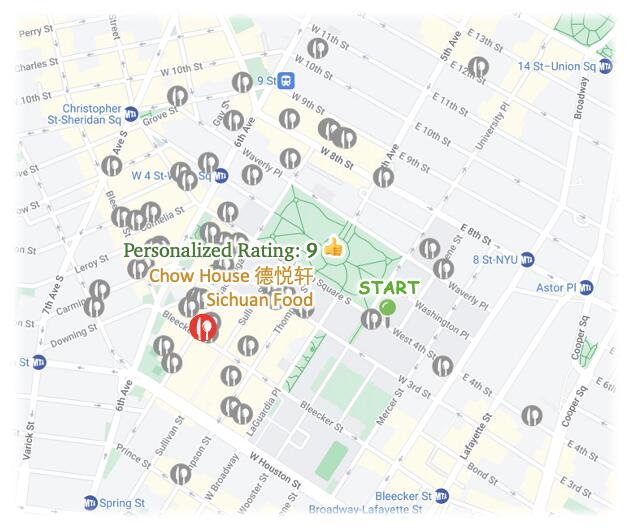
Aria: Place Recommender
Aria searches for possible restaurants nearby.
She then synthesizes public reviews to make final recommendations via GPT-4. As Peng is new to the city and originally from Sichuan, she recommends the spicy Chinese joint Chow House 粤德轩 to give him a taste of home.
Click to check different candidate places:
Example Place Review:
Well done, Chow House. Authentic cuisine, expertly prepared. Twice Cooked pork, done the right way. You can see the leeks from the photo with none of that Americanized garbage many places dump into this otherwise elegant dish... Big shrimp. Big flavor. Peanuts. Initially, I was scared of the deep fried dried red pepper, but they turned out really tasty and crunchy, not as spicy as I had originally feared. Pork fried rice, expertly cooked. All in all, if you live downtown and like authentic Sichuan food, this is your place. Bravo! (rating: 5)
Amazing Asian grill! Great taste, big variety, good prices... They have plenty of options vegan and non-vegan. The skewers are super affordable, fun to eat and taste great. Prices range from 50cents - 4$ per skewer, depending in what skewers, with most being around 2$. They deep fry the skewers right there for you and add salt and other spices (let them know if you don't like your food too salty). Highly recommended:).(rating: 5)
I was so impressed with my brunch. I tried the French toast, my boyfriend got the Eggs Benedict and our friend got the burger. The quality of the food is good and it takes a short amount of time to receive it. The staff was sweet and helpful. I will definitely come back. (rating: 5)
You must have to love sushi if you plan on dining here. It’s $299/person and omakase only... The sushi is flown in daily from Japan. It is definitely a dining experience for taste, texture and art of the making and presentation of each sushi. With a few glasses of wine and bottled water as well as tip was about $850. It’s quite expensive but I feel that the experience and quality of the food is worth it. It’s perfect for a special occasion. The sushi was the freshest sushi I’ve ever ate in my life. (rating: 5)
Very sad burrito for the price point. Very small small for the price point as you can see it is no bigger than my friends arm. There were things missing from the burrito such as pico and guac. Each bite I took I regretted. As a vegan I would say it’s better for your wallet and your stomach to go to chipotle. (rating: 2)
Agent Consideration:
Chow House is a highly recommended Sichuan restaurant, which aligns with Peng's background as he grew up in Sichuan. The restaurant offers authentic Sichuan food, which Peng might be familiar with and enjoy. The restaurant also has good seating, decoration, and friendly service, which would make for a pleasant dining experience. However, some dishes received mixed reviews, which is why the rating is not a perfect 10.
Takeaway
V-IRL exposes rich real-world information to agents that they can use for real-world tasks.
Vivek: Estate Agent
Vivek uses real estate APIs to find potential apartments in Peng's desired regions and price range.
For each candidate, he researches its proximity to the places Peng cares about. Synthesizing these factors, Vivek provides a holistic rating and accompanying reasoning using GPT-4.
His top recommendation is a cost-effective 1 bedroom apartment for $1986/mo, which is close to a supermarket, 2 bus stations, and a gym.
Part of candidate estates.
Takeaway
Grounded in geographic coordinates, V-IRL agents can leverage arbitrary real-world information via APIs.
Visually Grounded Agents
Although language-driven agents can address some real-world tasks using external tools, their reliance on solely text-based information limits their applicability to tasks where visual grounding is required.
In contrast, real sensory input is integral to many daily human activities—allowing a deep connection to and understanding of the
real world around us.
Agents can leverage street view imagery through the V-IRL platform to visually ground themselves in the real world—opening up a wide range of perception-driven tasks.
RX-399: Urban Assistance Robot
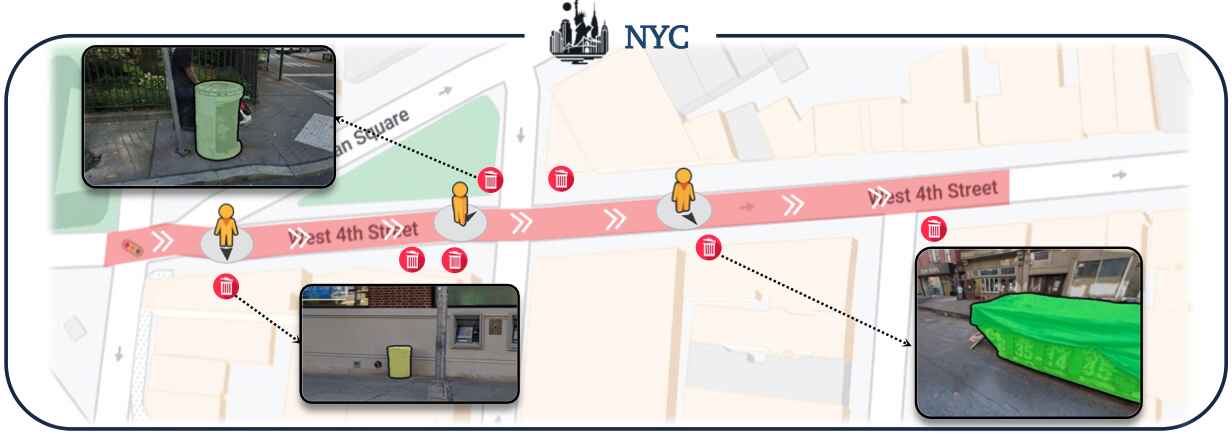
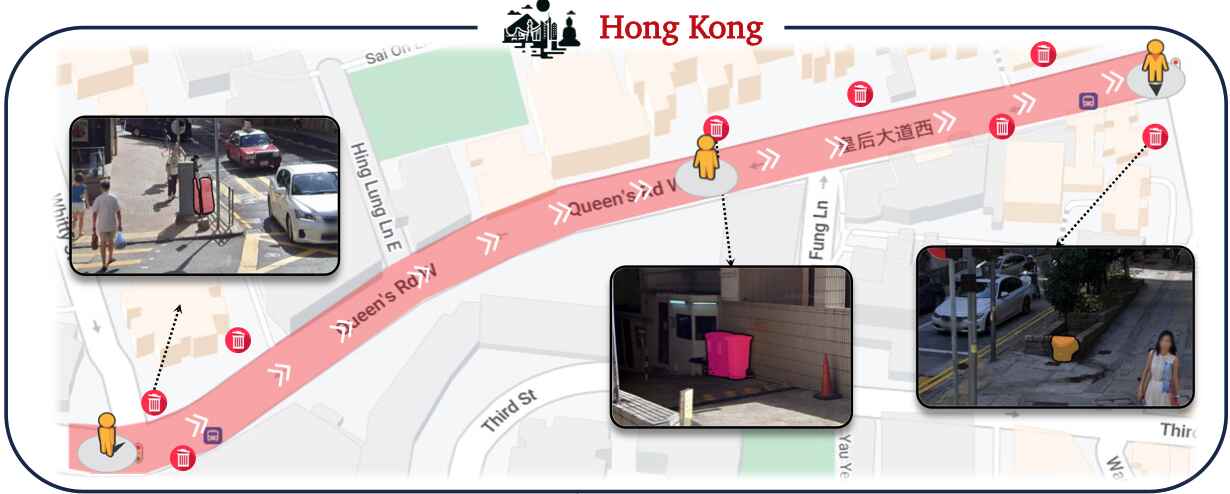
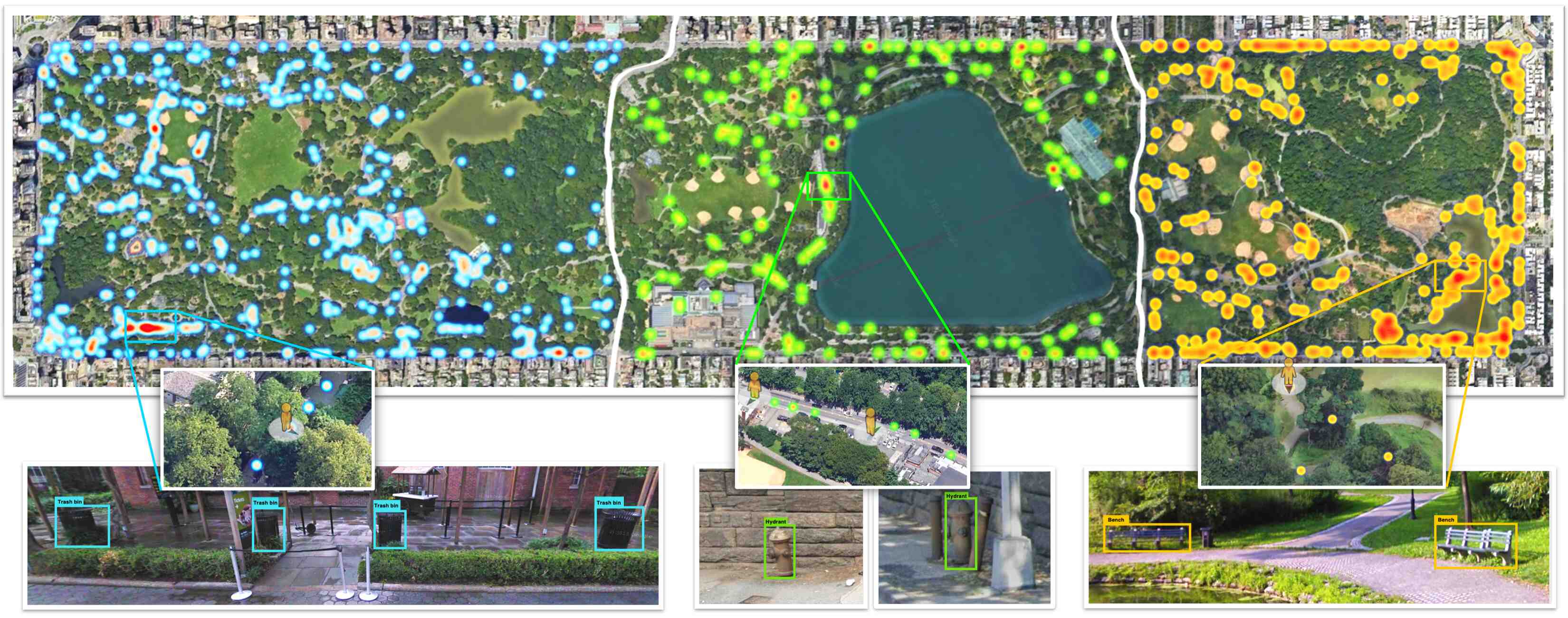
RX-399 navigates along pre-defined city routes, tagging all trash bins using its open-world detector and geolocation module as depicted in the following figure and videos.
V-IRL agents can use perceptual input to understand and interact with their environment.
Imani: Urban Planner
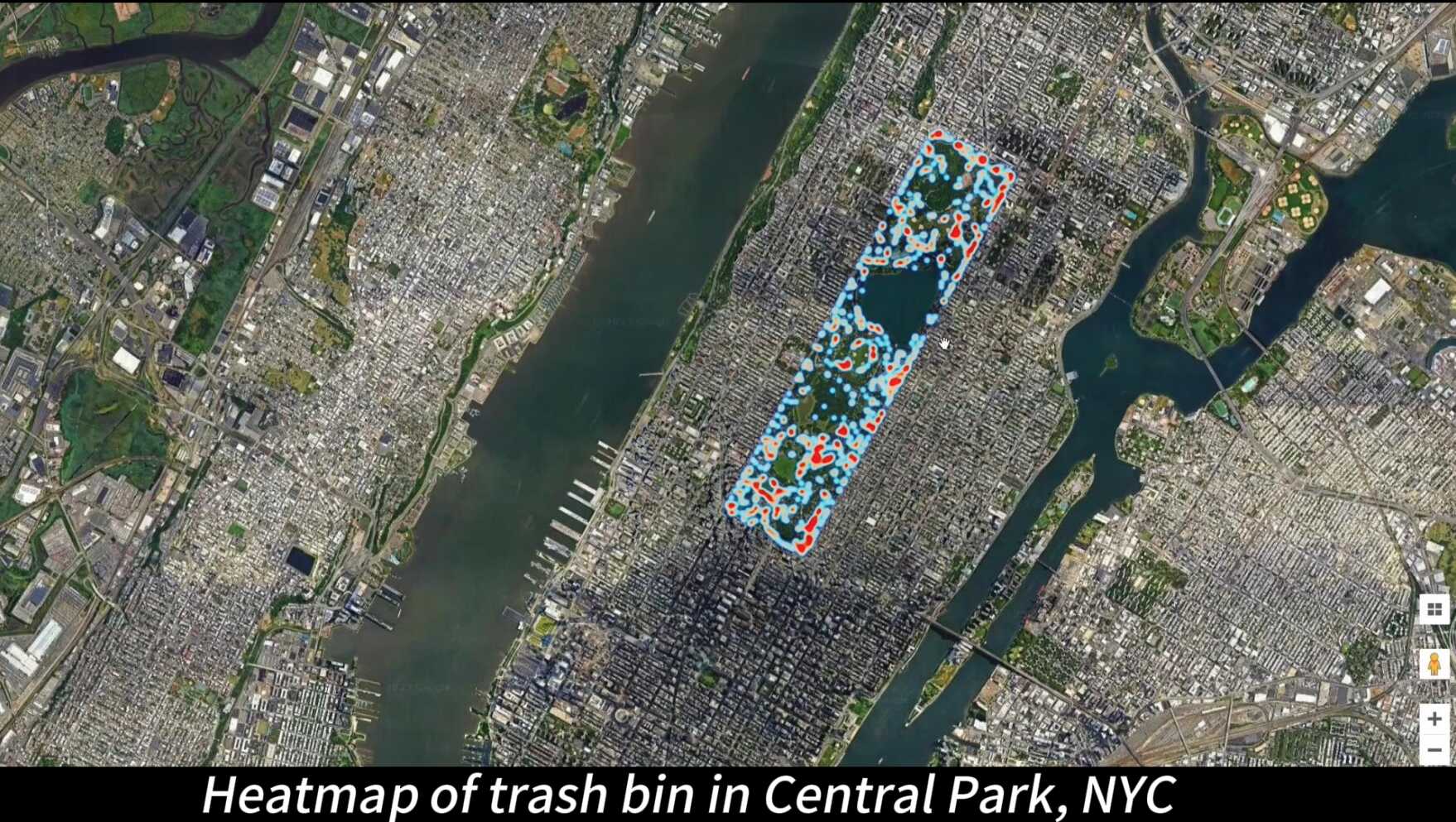
Imani sets routes spanning Central Park and objects of interest for RX-399, who traverses the routes and records all detected instances.
After RX-399 finishes its route, Imani analyzes the collected data by RX-399 at different levels of detail.
Imani's visualization of trash bins, fire hydrants, park benches in NYC's Central Park using data collected by RX-399. The coarsest level shows general distributions of trash bins, hydrants, and benches in the park.
Imani can also zoom in to specific regions, where lighter colors represent positions with more unique instances identified.
Switch videos between data collecting and heatmap distribution:
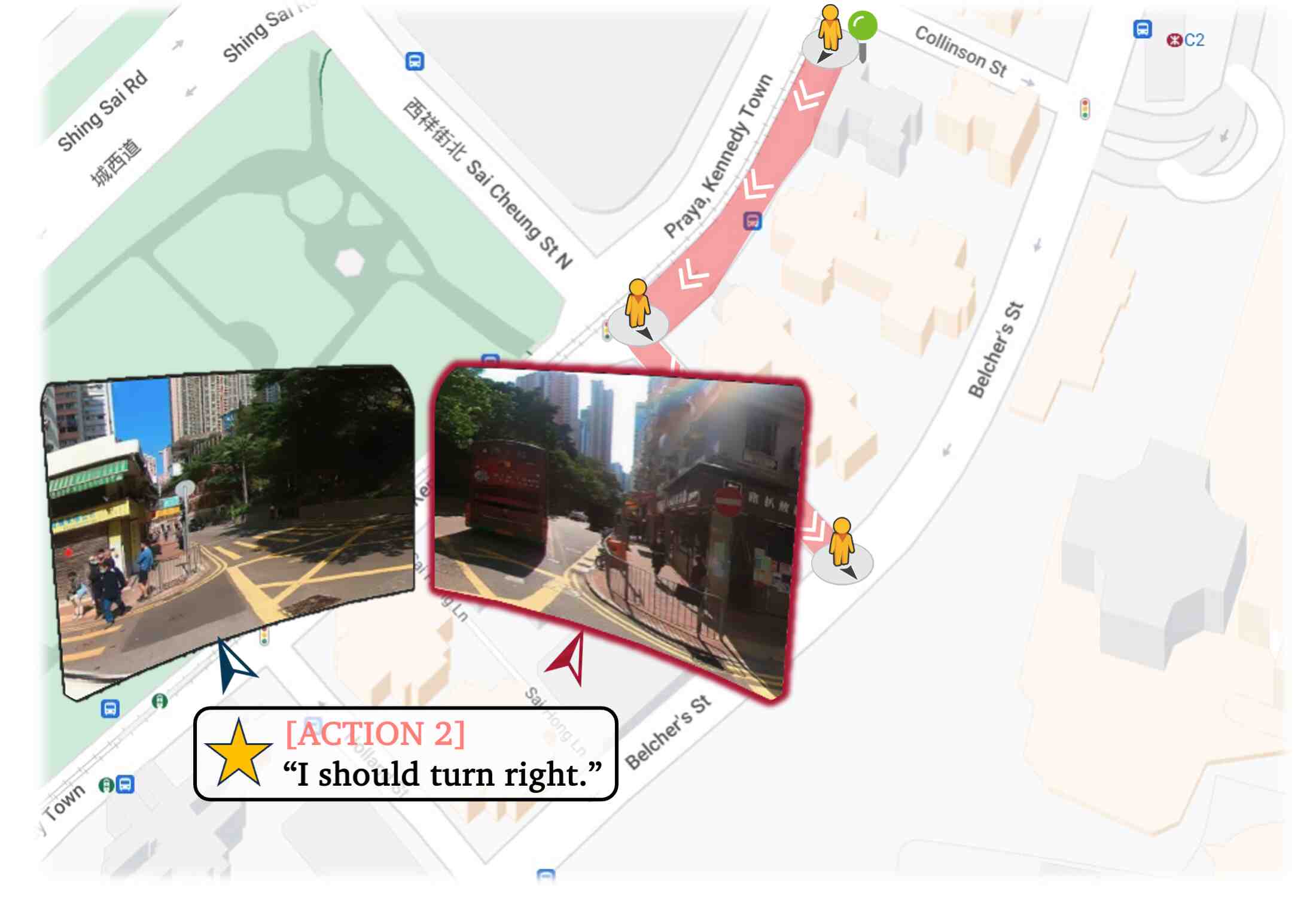
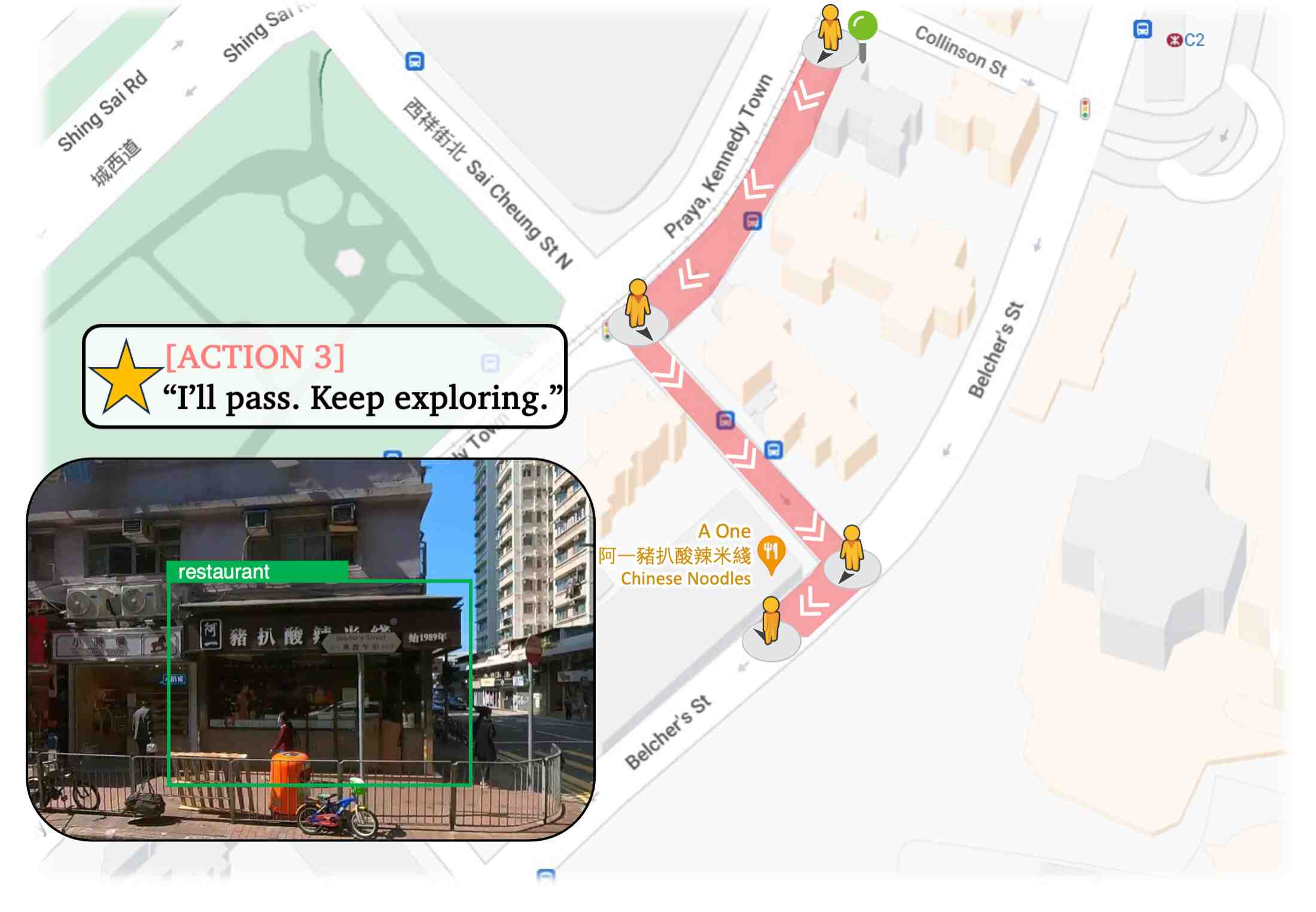
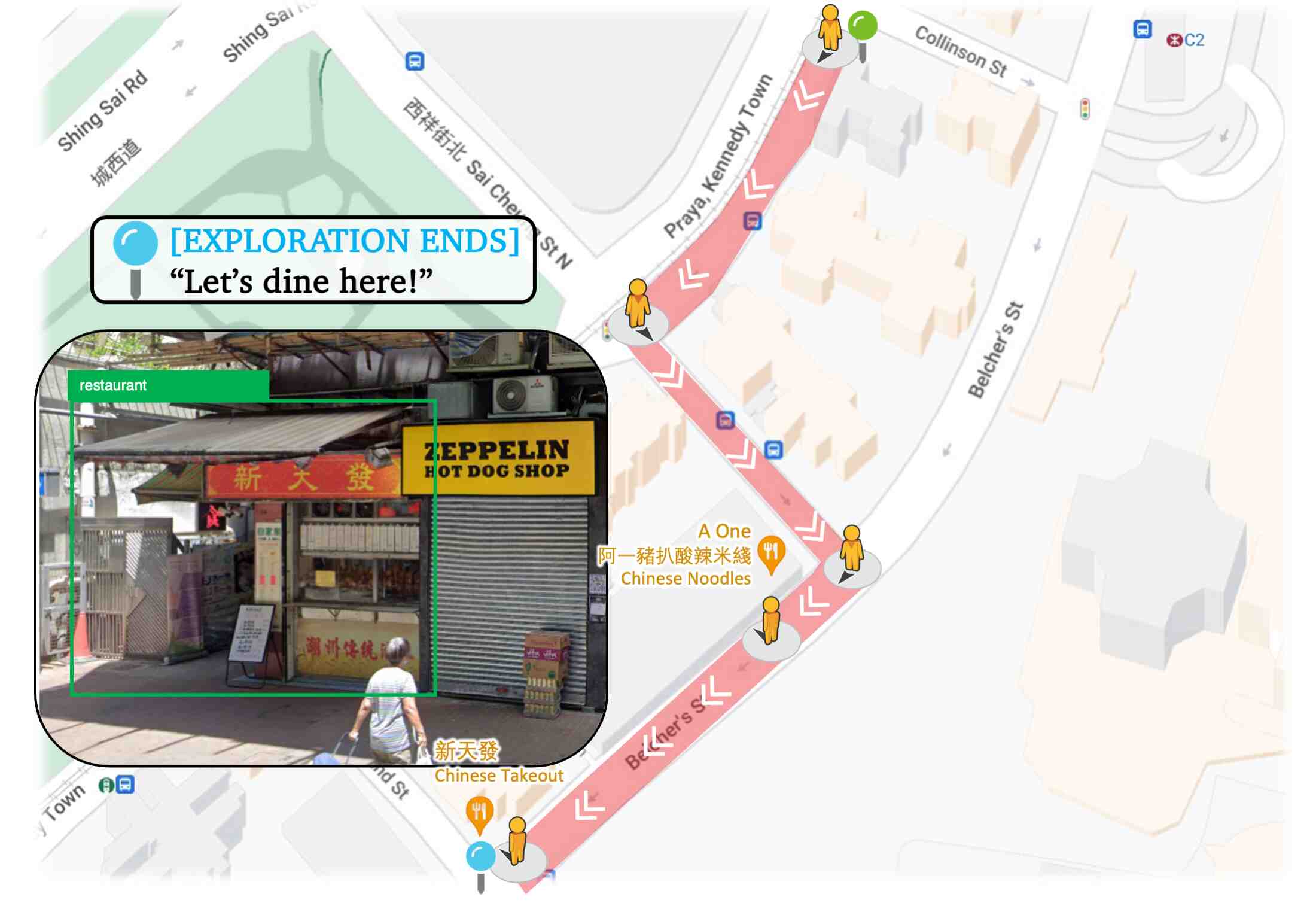
Driven by his intention, Hiro uses open-world detection to find a restaurant; uses VQA to select proper roads; uses place reviews and LLM to decide whether a place is suitable for his purpose.
Milestone 1 / 5
Milestone 2 / 5
Milestone 3 / 5
Milestone 4 / 5
Milestone 5 / 5
❮❯Visualization for Hiro's lunch exploration in HK. Concrete procedure is depicted in the following video.
Takeaway
V-IRL agents can utilize visual detectors, VLMs and LLMs to iteratively perceive, decide, and interact in the environment.
Collaborative Agents
Humans often work together to solve complex real-world tasks. This collaboration promotes efficiency and effectiveness by decomposing a complex task into simpler sub-tasks, allowing each to be handled by an expert in its domain.
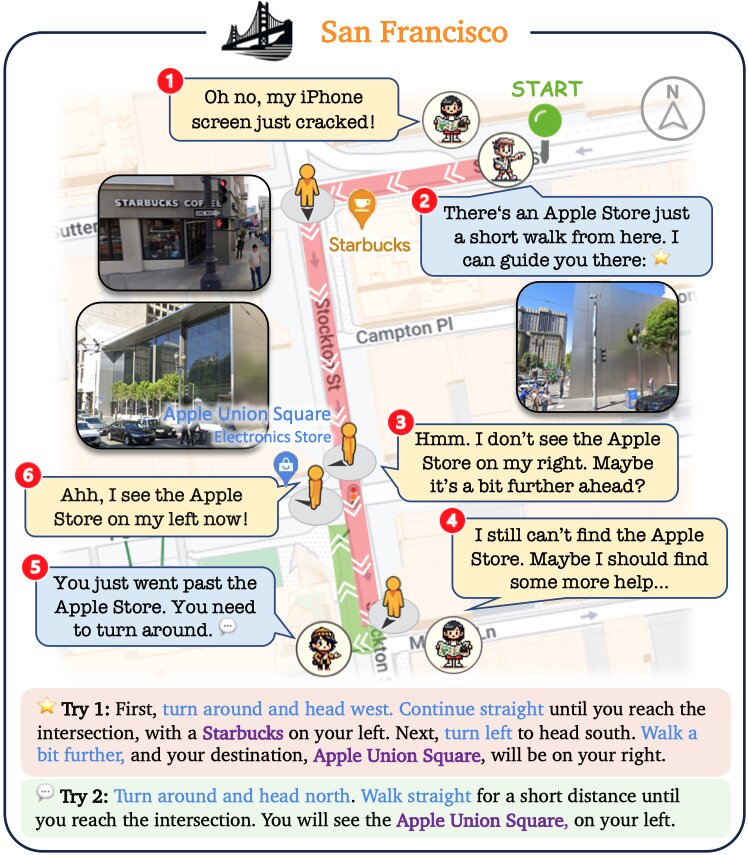
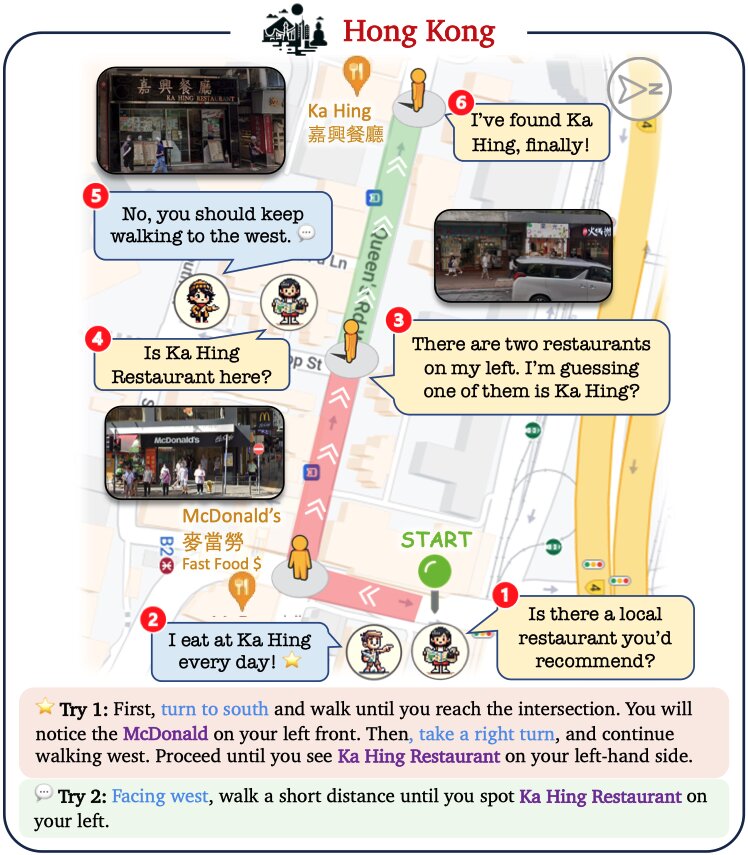
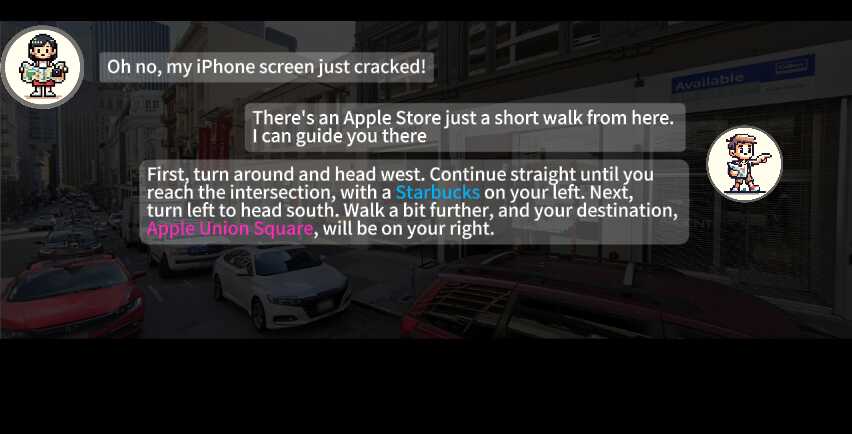
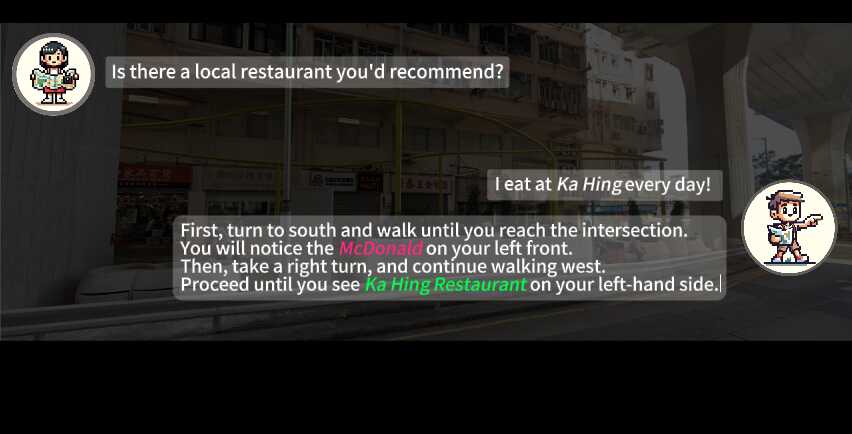
Ling: Tourist
After obtaining route descriptions from Locals, Ling starts her journey. Grounded in our embodied platform, Ling can adjust her pose and identify visual landmarks along the streets using open-world recognition and her map. Recognizing these landmarks helps GPT-4 to make correct decisions about where to turn direction, move forward and stop. Concrete examples are shown in the following figure and videos.
V-IRL agents can collaborate to solve complex tasks that are beyond their individual expertise.
Diego: Expert Concierge
As depicted in the following figure, Diego's itinerary is tailored to your needs. Diego not only considers your physical and mental interoception status, budget for each activity, but also anticipates your status changes and cost when you follow each event.
He is able to take into account real travel times from the V-IRL platform and select suitable dining options by collaborating with another
restaurant recommendation agent.
The Perfect Day Itinerary: Crafted by Diego, our iterative concierge agent, this schedule is meticulously tailored, accounting for your mental and physical well-being and budget variations as your day unfolds.
You can intervene Diego's planning process by adjusting your interoception status or providing verbal feedback for Diego.
In response, Diego promptly revises his original plan to make it accommodate your demands, and re-estimate your state changes after revision. (see the following figures)
Diego adapts original plan to suit user's intervention.
Behind Diego's proficiency in developing itineraries is his iterative planning pipeline.
The process begins with Diego creating an initial draft plan for the first activity using GPT-4, taking into account the user's biography, requirements, and previous activities in working memory. This draft is then meticulously refined by hierarchical coordination (real geospatial/place information), interoceptive estimation (activity cost and influence for human states) and supervisor (human interoception, budget and potential intervention).
Pipeline overview of interactive concierge agent Diego.
Additionally, grounded on tightly related street views and Map in V-IRL, Diego travels places in his itinerary to scout for potential scenic viewpoints for you as shown in the following figure.
He uses VQA to assess each captured views, attaching highly rated positions to your itinerary.
Geo Location: [40.8649162, -73.9311561]
Geo Location: [40.8647205, -73.9325163]
Geo Location: [40.8653388, -73.9322499]
Geo Location: [40.8609142,-73.9324818]
Geo Location: [40.8642401,-73.9325958]
❮❯Diego rates scenery and records attractive locations in your itinerary.
Takeaway
V-IRL agents can collaborate with users to solve complex tasks that require understanding the user's internal state.
System Fundamentals
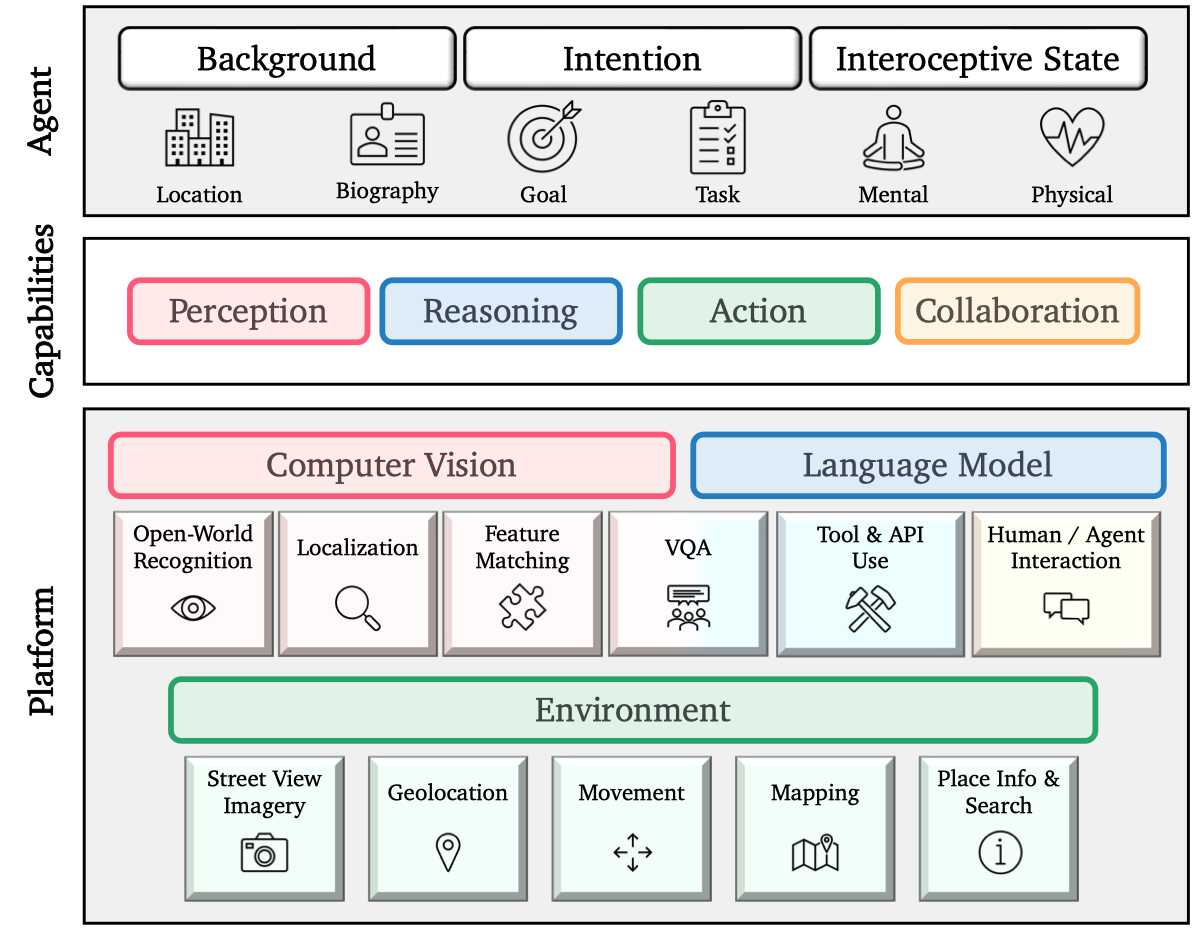
Here we describe V-IRL's hierarchical architecture that transforms real cities around the world into a vast virtual playground in which agents can be constructed to solve practical tasks.
The platform lies at the foundation—providing the underlying components and infrastructure for agents to employ.
Higher level capabilities of Perception, Reasoning, Action, and Collaboration emerge from the platform's components.
Finally, agents leverage these capabilities along with user-defined metadata in task-specific run() routines to solve tasks.
Click on any individual module to view its detailed description
Hierarchical V-IRL architecture.
V-IRL Benchmark
The essential attributes of V-IRL include its ability to access geographically diverse data derived from real-world sensory input, and its API that facilitates interaction with Google Map Platform (GMP) .
This enables us to develop three V-IRL benchmarks to assess the capabilities of existing vision models in such open-world data distribution.
V-IRL Place: Localization
Motivation: Every day, humans traverse through cities, moving between diverse places to fulfil a range of goals, like the Intentional Explorer agent.
We assess the performance of vision models on the everyday human activity place localization using street view imagery and associated place data.
Setups: We modify RX-399 agent to traverse polygonal areas while localizing & identifying 20 types of places.
We evaluate three prominent open-world detection models: GroundingDINO , GLIP , Owl-ViT , OpenSeeD and Owl-ViT v2 . We also implement a straightforward baseline, CLIP (w/ GLIP proposal), which involves reclassifying the categories
of GLIP proposals with CLIP .
Models are evaluated on localization recall, which is quantified as
, where
and
represents the number of correctly localized places and missed places, respectively.
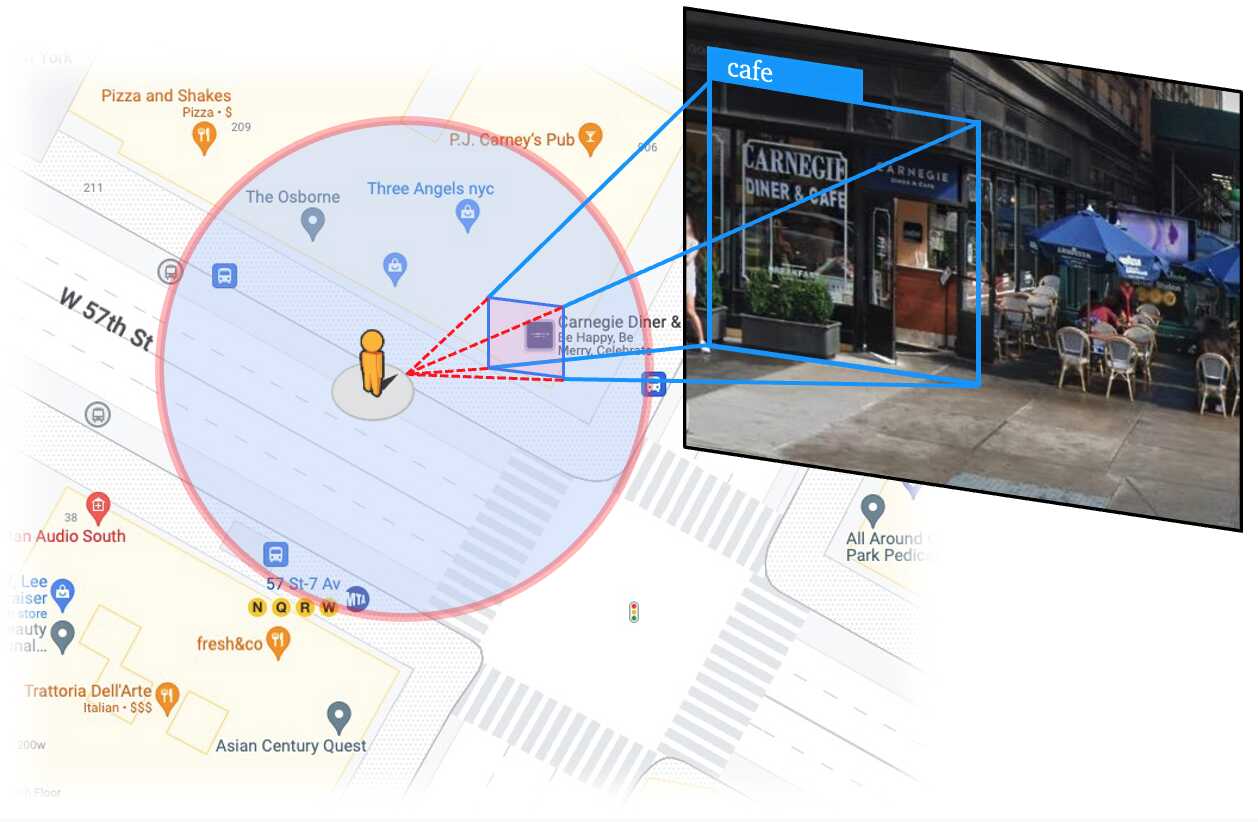
Matching between 2D object proposal and street place. we first project the bounding box of each object proposal onto a frustum in the 3D space, subject to a radius.
We then determine if any nearby places fall within this frustum and radius.
If any nearby place is found, the closest one is assigned as the ground truth for the object proposal. Otherwise, the object proposal is regarded as a false positive.
When multiple places are inside the frustum, we consider the nearest one as the ground truth since it would likely block the others in the image.
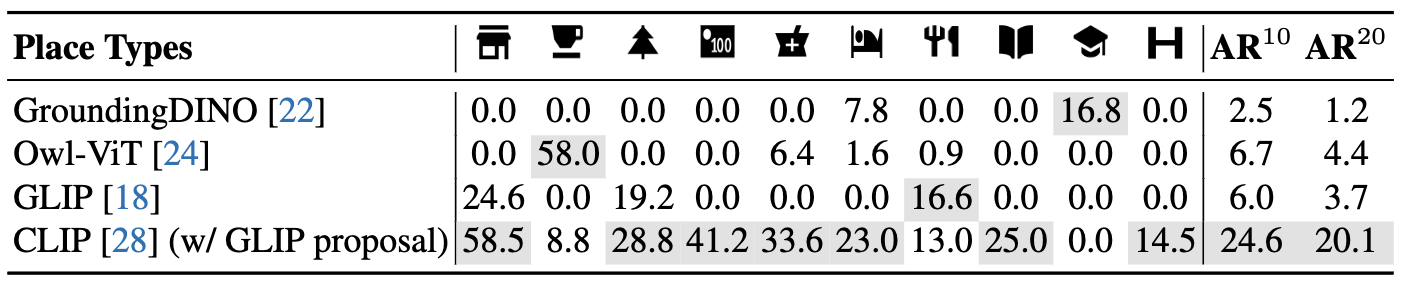
Results: Following table shows that open-world detectors like GroundingDINO , Owl-ViT and GLIP are biased towards certain place types such as school, cafe, and convenience store, respectively.
In contrast, CLIP (w/ GLIP proposal) can identify a broader spectrum of place types.
This is mainly caused by the category bias in object detection datasets with a limited vocabulary.
Hence, even if detectors like Owl-ViT are initialized with CLIP, their vocabulary space narrows down due to fine-tuning.
These results suggest that cascading category-agnostic object proposals to zero-shot recognizers appears promising for "real" open-world localization, especially for less common categories in object detection datasets.
Benchmark results on V-IRL Place Localization. and denote average recall on subsampled 10 and all 20 place categories, respectively. More results in paper.
Part of V-IRL Place localization benchmark results via CLIP (w/ GLIP proposal).
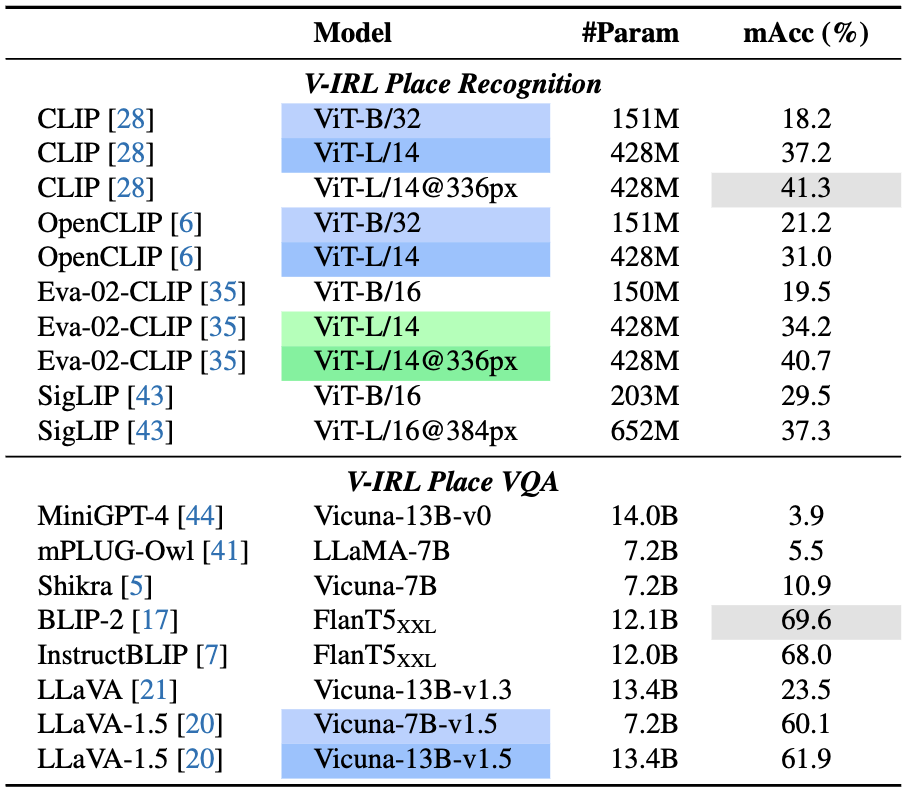
V-IRL Place: Recognition and VQA
Motivation: In contrast to the challenging V-IRL place localization task on street view imagery, in real life, humans can recognize businesses by taking a closer, place-centric look.
In this regard, we assess existing vision models on two perception tasks based on place-centric images: i) recognizing specific place types; ii) identifying human intentions by Vision Question Answering (VQA), named intention VQA.
Setups: For recognition, we assess 10 open-world recognition models, for place type recognition from 96 options, using place-centric images (see below imagery illustration).
❮❯Street view imagery (left), sourced from the Google Street View database, are taken from a street-level perspective, encompassing a broad view of the surroundings, including multiple buildings.
Place-centric imagery (right), drawn from the Google Place database, focus predominantly on the specific place, providing a more concentrated view.
For intention VQA, we also evaluate 13 multi-modal large language models (MM-LLM) to determine viable human intentions from a four-option multiple-choice VQA. The V-RL Place VQA process is illustrated in following image, where the candidate and true choices are generated by GPT-4 given the place types and place names corresponding to the image.
Example of V-RL Place VQA process.
Results: Following table shows that CLIP (L/14@336px) outperforms even the biggest version of Eva-02-CLIP and SigLIP in the V-RL Place recognition task, emphasizing the high-quality data of CLIP.
The bottom of the table shows that LLaVA-NeXT (7B) outperforms its predecessors LLaVA-1.5 and 1.0, but still has over 8% gap to InternVL-1.5 with 26B parameters. Closed-source MLLMs GPT-4V and Qwen-VL-Max yield outstanding performance compared to most open-sourced models.
We note that even these top-performing MLLMs (e.g. GPT-4V and Qwen-VL-Max) still suffer from inconsistent issues during the circular evaluation .
Moreover, vision models perform better on place VQA over place-type recognition, suggesting direct prompts about human intention could be more effective for intention-driven tasks.
Benchmark results on V-RL Place recognition and V-RL Place VQA. Green indicates increased resolution models, while Blue denotes model parameter scaling.
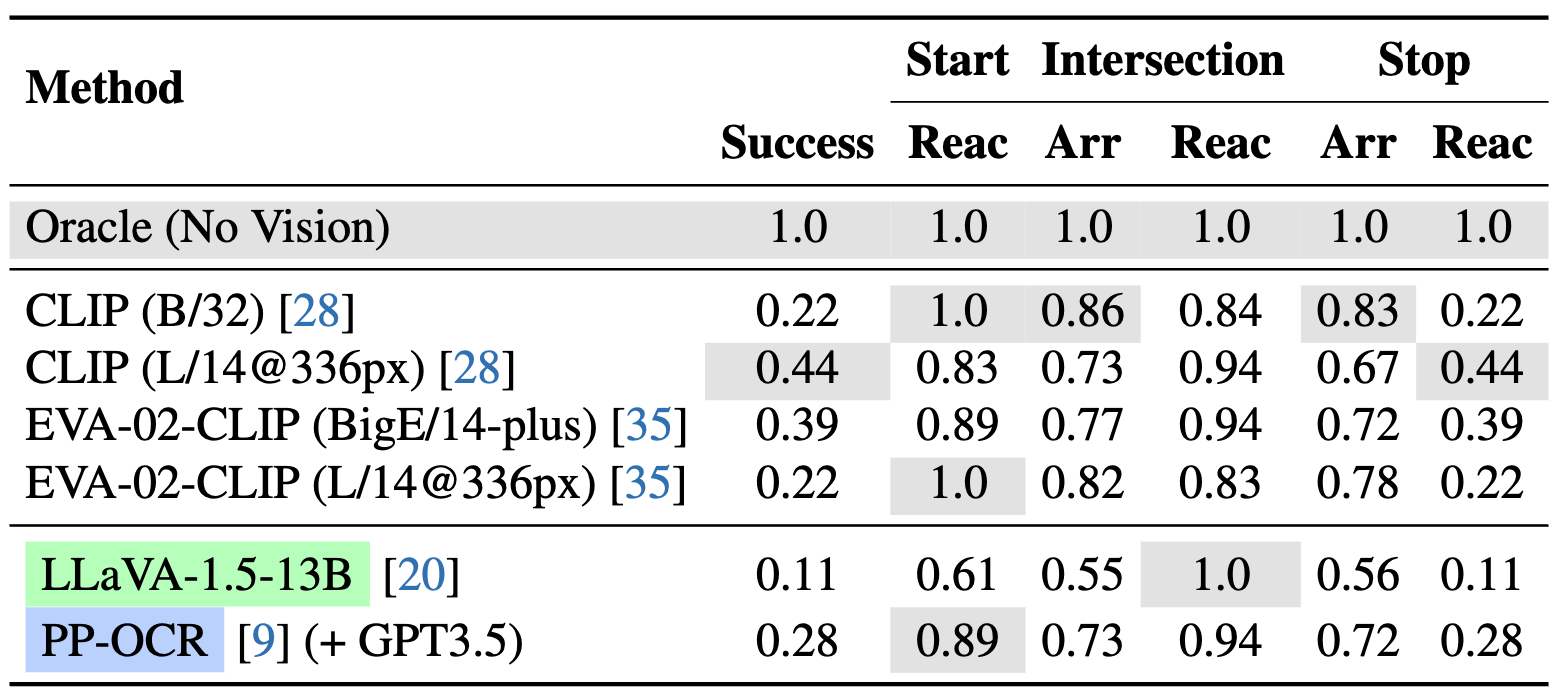
V-IRL Vision Language Navigation
Motivation: As discussed in the V-IRL agents section, Intentional Explorer and Tourist agents require collaboration between vision models and language models to accomplish complex tasks. Therefore, this motivates us to investigate the performance of vision-language collaboration, with environmental information acquired through visual perception models from real-world images.
This prompts us to build an embodied task for jointly leveraging vision and language models along with the realistic street views in V-IRL.
In this regard, we build this V-IRL Vision Language Navigation (VLN) benchmark.
Setups: We adapt the Tourist agent implementation and replace its recognition component with the various benchmarked models. These methods are tasked to identify visual landmarks during navigation. Subsequently, GPT-4 predicts the next action according to the recognition results. Navigation instructions are generated using the Local agent.
Four approaches are evaluated to recognize landmarks during navigation: (i) Approximate oracle by searching nearby landmarks; (ii) Zero-shot recognizers CLIP and EVA-02-CLIP ; (iii) Multi-modal LLM LLaVA-1.5 (iv) OCR model to recognize potential text in street views followed by GPT answer parsing.
Results: Following table shows that, with oracle landmark information, powerful LLMs can impressively comprehend navigation instructions and thus make accurate decisions. However, when using vision models to fetch landmark information from street views, the success rate drops dramatically, suggesting that the perception of vision models is noisy and misguides LLMs' decision making. Among these recognizers, larger variants of CLIP and EVA-02-CLIP perform better, highlighting the benefits of model scaling. LLaVA-1.5 shows inferior performance with CLIP (L/14@336px) as its vision encoder, possibly due to the alignment tax during instruction tuning.
Further, PP-OCR (+ GPT-3.5) achieves a 28% success rate, signifying that OCR is crucial for visual landmark recognition.
Results on V-IRL VLN-mini. We test various CLIP-based models, MM-LLM, and OCR model with GPT postprocessing. We primarily measure navigation success rate (Success). In addition, as navigation success is mainly influenced by the agent's actions at key positions (i.e., start positions, intersections and stop positions), we also evaluate the arrival ratio (Arr) and reaction accuracy (Reac) for each route. Arr denotes the percentage of key positions reached, while Reac measures the accuracy of the agent's action predictions at these key positions. Full-set results on CLIP and Oracle are available in paper appendix.
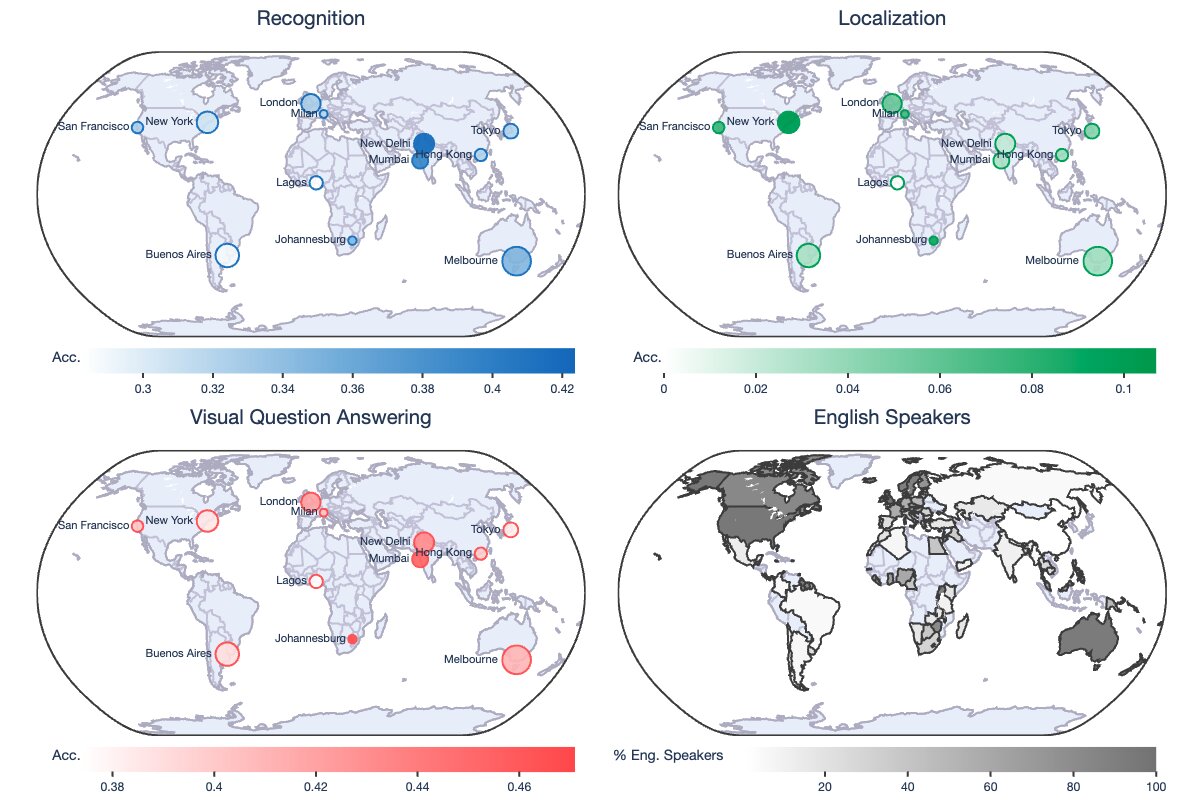
Geographic Diversity
Spanning 12 cities across the globe, our V-IRL benchmarks provide an opportunity to analyze the inherent model biases in different regions. As depicted in the following figure, vision models demonstrate subpar performance on all three benchmark tasks in Lagos, Tokyo, Hong Kong, and Buenos Aires.
In Lagos, vision models might struggle due to its non-traditional street views relative to more developed cities (see street views in aside figures). For cities like Tokyo, Hong Kong and Buenos Aires, an intriguing observation is their primary use of non-English languages in street views.
This suggests that existing vision models face challenges with multilingual image data.
City-level visualization of V-IRL benchmark results.
Discussion: Ethics & Privacy
Our platform serves as a tool for AI development and as a crucible for ethical discourse and preparation. As AI is inevitably being integrated into society—e.g., via augmented reality wearables or robots navigating city streets—it is imperative to confront and discuss ethical and privacy concerns now. Unlike these impending real-time systems, the data accessed by V-IRL is "stale" and often preprocessed—providing a controlled environment to study these concerns.
Notably, V-IRL exclusively utilizes preexisting, readily available APIs; it does not capture or make available any previously inaccessible data. Our primary source of street-view imagery, Google Maps, is subject to major privacy-protection measures, including blurring faces and license plates .
Moreover, V-IRL complies with the Google Maps Platform license, similarly to notable existing works that also leverage Google's street views .
We believe V-IRL is an invaluable tool for researching bias. As discussed in geographic diversity, V-IRL's global scale provides a lens to study linguistic, cultural, and other geographic biases inherent in models. By using V-IRL to study such questions, we aim to preemptively tackle the ethical dilemmas that will arise with deploying real-time systems rather than being blindsided by them. We hope our work helps spur proactive discussion of future challenges throughout the community.
Conclusion
In this work, we introduce V-IRL, an open-source platform designed to bridge the sensory gap between the digital and physical worlds, enabling AI agents to interact with the real world in a virtual yet realistic environment.
Through V-IRL, agents can develop rich sensory grounding and perception, utilizing real geospatial data and street-view imagery.
We demonstrate the platform's versatility by creating diverse exemplar agents and developing benchmarks measuring the performance of foundational language and vision models on open-world visual data from across the globe.
This platform opens new avenues for advancing AI capabilities in perception, decision-making, and real-world data interaction.
As spatial computing and robotic systems become increasingly prevalent, the demand for and possibilities of AI agents will only grow.
From personal assistants to practical applications like urban planning to life-changing tools for the visually impaired, we hope V-IRL helps usher in a new era of perceptually grounded agents.
BibTeX
@inproceedings{yang2024virl,
title={{V-IRL: Grounding Virtual Intelligence in Real Life}},
author={Yang, Jihan and Ding, Runyu and Brown, Ellis and Qi, Xiaojuan and Xie, Saining},
year={2024},
booktitle={European conference on computer vision},
}